Installation
library("devtools")
install_github("NSAPH-Software/GPCERF", ref = "main")Usage
Estimating GPS values
Input parameters:
cov_mt Covariate matrix containing all
covariates. Each row represents a sample, and each column is a
covariate.w_all A vector of observed exposure
level.
mydata <- generate_synthetic_data()
gps_m <- estimate_gps(cov_mt = mydata[, c("cf1", "cf2", "cf3", "cf4",
"cf5", "cf6")],
w_all = mydata$treat,
sl_lib = c("SL.xgboost"),
dnorm_log = FALSE)
#> Loading required package: nnlsEstimating exposure response using Gaussian Processes
Input parameters:
data A data.frame of observation
data.
- Column 1: Outcome (Y)
- Column 2: Exposure or treatment (w)
- Column 3~m: Confounders (C)w A vector of exposure level to compute
CERF.gps_m A data.frame of GPS vectors.
- Column 1: GPS
- Column 2: Prediction of exposure for covariate of each data sample
(e_gps_pred)
- Column 3: Standard deviation of e_gps (e_gps_std)params A list of parameters that is
required to run the process.
- alpha: A scaling factor for the GPS value.
- beta: A scaling factor for the exposure value.
- g_sigma: A scaling factor for kernel function (gamma/sigma).
- tune_app: A tuning approach. Available approaches:
- all: try all combinations of hyperparameters.
alpha, beta, and g_sigma can be a vector of parameters.
nthread An integer value that
represents the number of threads to be used in a shared memory
system.kernel_fn A kernel function. A default
value is a Gaussian kernel.
set.seed(129)
sim_data <- generate_synthetic_data(sample_size = 400, gps_spec = 3)
# Estimate GPS function
gps_m <- estimate_gps(cov_mt = sim_data[, -(1:2)],
w_all = sim_data$treat,
sl_lib = c("SL.xgboost"),
dnorm_log = TRUE)
# exposure values
q1 <- stats::quantile(sim_data$treat, 0.05)
q2 <- stats::quantile(sim_data$treat, 0.95)
w_all <- seq(q1, q2, 1)
params_lst <- list(alpha = c(0.05),
beta = c(12),
g_sigma = c(0.1),
tune_app = "all")
cerf_gp_obj <- estimate_cerf_gp(sim_data,
w_all,
gps_m,
params = params_lst,
outcome_col = "Y",
treatment_col = "treat",
covariates_col = paste0("cf", seq(1,6)),
nthread = 1)
summary(cerf_gp_obj)
#> GPCERF standard Gaussian grocess exposure response function object
#>
#> Optimal hyper parameters(#trial: 1):
#> alpha = 0.05 beta = 12 g_sigma = 0.1
#>
#> Optimal covariate balance:
#> cf1 = 0.080
#> cf2 = 0.081
#> cf3 = 0.111
#> cf4 = 0.119
#> cf5 = 0.084
#> cf6 = 0.104
#>
#> Original covariate balance:
#> cf1 = 0.185
#> cf2 = 0.161
#> cf3 = 0.106
#> cf4 = 0.208
#> cf5 = 0.246
#> cf6 = 0.283
#> ----***----
plot(cerf_gp_obj)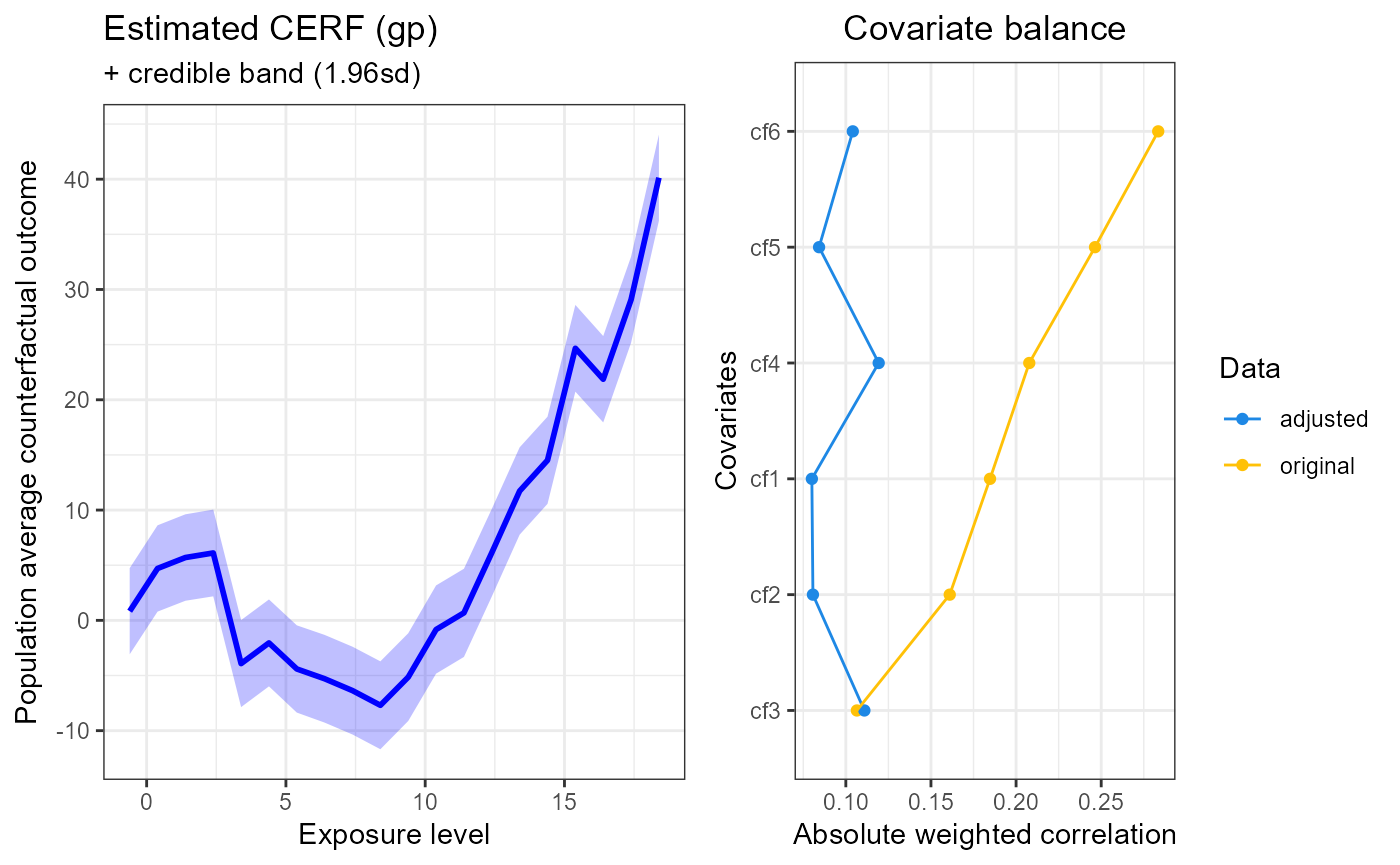
Estimating exposure response using nearest-neighbor Gaussian Processes
Input parameters:
data A data.frame of observation
data.w A vector of exposure level to compute
CERF.gps_m A data.frame of GPS vectors.
- Column 1: GPS
- Column 2: Prediction of exposure for covariate of each data sample
(e_gps_pred)
- Column 3: Standard deviation of e_gps (e_gps_std)params A list of parameters that is
required to run the process.
- alpha: A scaling factor for the GPS value.
- beta: A scaling factor for the exposure value.
- g_sigma: A scaling factor for kernel function (gamma/sigma).
- tune_app: A tuning approach. Available approaches:
- all: try all combinations of hyperparameters.
- n_neighbors: Number of nearest neighbors on one side.
- block_size: Number of samples included in a computation block. Mainly
used to balance speed and memory requirement. Larger is faster, but
requires more memory.
alpha, beta, and g_sigma can be a vector of parameters.
outcome_col An outcome column name in
data. treatment_col A
treatment column name in data.
covariates_col Covariates columns name in
data.
nthread An integer value that
represents the number of threads to be used in a shared memory
system.kernel_fn A kernel function. A default
value is a Gaussian kernel.
set.seed(19)
sim_data <- generate_synthetic_data(sample_size = 1000, gps_spec = 3)
# Estimate GPS function
gps_m <- estimate_gps(cov_mt = sim_data[, -(1:2)],
w_all = sim_data$treat,
sl_lib = c("SL.xgboost"),
dnorm_log = TRUE)
# exposure values
q1 <- stats::quantile(sim_data$treat, 0.05)
q2 <- stats::quantile(sim_data$treat, 0.95)
w_all <- seq(q1, q2, 1)
params_lst <- list(alpha = c(0.05),
beta = c(12),
g_sigma = c(0.1),
tune_app = "all",
n_neighbor = 20,
block_size = 1e4)
cerf_nngp_obj <- estimate_cerf_nngp(sim_data,
w_all,
gps_m,
params = params_lst,
outcome_col = "Y",
treatment_col = "treat",
covariates_col = paste0("cf", seq(1,6)),
nthread = 1)
summary(cerf_nngp_obj)
#> GPCERF nearest neighbore Gaussian process exposure response function object summary
#>
#> Optimal hyper parameters(#trial: 1):
#> alpha = 0.05 beta = 12 g_sigma = 0.1
#>
#> Optimal covariate balance:
#> cf1 = 0.118
#> cf2 = 0.103
#> cf3 = 0.105
#> cf4 = 0.089
#> cf5 = 0.159
#> cf6 = 0.149
#>
#> Original covariate balance:
#> cf1 = 0.136
#> cf2 = 0.148
#> cf3 = 0.105
#> cf4 = 0.228
#> cf5 = 0.184
#> cf6 = 0.280
#> ----***----
plot(cerf_nngp_obj)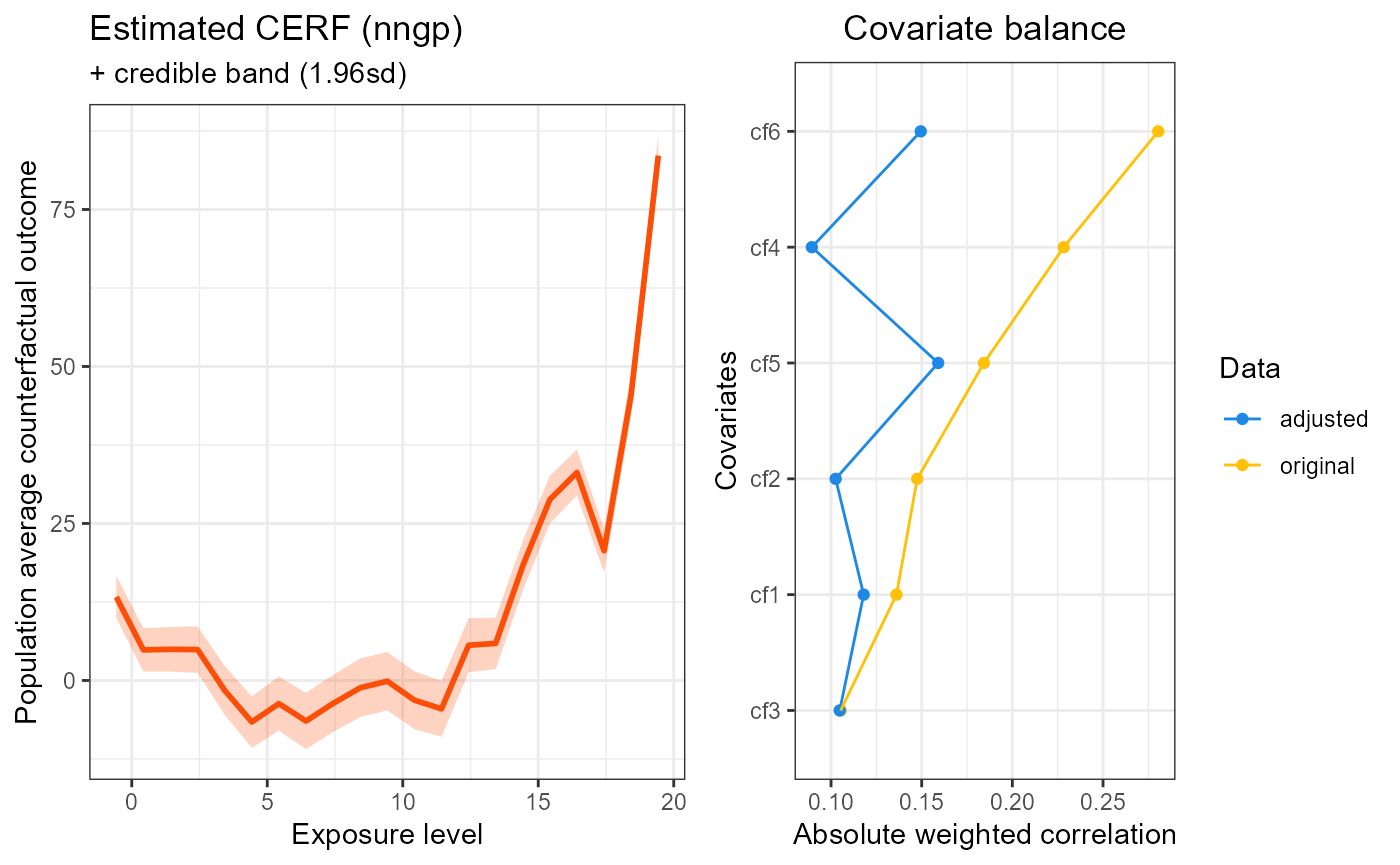
Logging
The GPCERF package logs internal activities into the screen or
GPCERF.log file. Users can change the logging file name
(and path) and logging threshold. The logging mechanism has different
thresholds (see logger package).
The two most important thresholds are INFO and DEBUG levels. The former,
which is the default level, logs more general information about the
process. The latter, if activated, logs more detailed information that
can be used for debugging purposes. The log file is located in the
source file location and will be appended.